KoBART - 문서 요약 모델
KoBART
KoBART는 SKT 에서 공개한 한국어 모델이다. 그외 KoBERT, KoGPT 도 있으니 관심있으면 찾아보길 권한다.
SKT에서 모델을 공개한 것에 대해 감사함을 표한다.
KoBART Github에 들어가면 예제로 아래 5개를 따라해볼 수 있다.
- KoBART ChitChatBot
- KoBART Summarization
- NSMC Classification
- KoBART Translation
- LegalQA using SentenceKoBART
그중 Summarization 파트를 seujung 라는 분이 모델 패키징을 잘 해주셔서 솔직히 클론부터 running 체크까지 5분도 안걸린 것 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
git clone https://github.com/seujung/KoBART-summarization.git
cd KoBART-summarization
pip install git+https://github.com/SKT-AI/KoBART#egg=kobart
pip install -r requirements.txt
cd data
tar -zxvf train.tar.gz
tar -zxvf test.tar.gz
cd ../
python train.py --gradient_clip_val 1.0 --max_epochs 50 --default_root_dir logs --gpus 1 --batch_size 4 --num_workers 4
Dataset sample
PC로 봐야 그나마 볼만함.
- 원문
계약금 10%·중도금무이자융자·6개월 후 전매가능 기자 아파트 분양시장이 실수요자 중심으로 바뀌면서 초역세권 입지와 변화하는 라이프스타일에 맞춘 혁신평면이 아파트 선택에 미치는 영향력이 커지고 있다. 태왕이 지난 22일 공개한 ‘성당 태왕아너스 메트로’ 모델하우스를 찾은 방문객들은 초역세권 입지에다 혁신평면에 다시 한번 호평을 보냈다. 오픈 당일 문을 열기 전부터 관람객의 줄이 이어지면서 꽃샘추위의 궂은 날씨에도 주말까지 관람객의 발길이 끊이지 않았다. 이 단지는 서부정류장역 초역세권인데다 단지방향으로 지하철 출입구가 추가설치 될 계획이다. 또 평면에서는 도심역세권에서 만나기 어려운 공간 활용성이 탁월한 와이드 84㎡라는 점에서 주목받았다. 특히 주방 팬트리와 안방 워크인드레스룸 등 수납특화에 큰 관심을 보였다. 분양관계자는 “성당동 유일의 초역세권아파트인데다 실수요자들이 혁신평면에 매우 만족하고 있다. 또 합리적인 분양가와 중도금무이자 등의 분양조건도 실수요자에게 유리해 높은 청약경쟁률을 기대한다”고 밝혔다. LG U+ 기반의 첨단ICT 솔루션 AI스마트홈 시스템을 적용한 인공지능아파트로 음성인식이 가능한 AI스피커를 제공해 인공지능 ICT플랫폼을 기반으로 한 다양한 첨단서비스를 누릴 수 있는 점도 장점이다. 또 지하주차장 주차차량 위치인식, 공동현관 자동문열림, 홈네트워크 연동 무인택배시스템, 공동현관 E/V 자동호출 등 원패스카드 하나로 다 누리는 아너스 원패스시스템도 적용된다. 분양관계자는 “성당동 유일의 초역세권아파트인데다 실수요자들이 혁신평면에 매우 만족하고 있다. 합리적인 분양가와 중도금무이자 등의 분양조건도 실수요자에게 유리해 높은 청약경쟁률을 기대한다”고 전망했다. 아파트의 경우 27일 특별공급을 시작으로 28일 1순위, 29일에 2순위 청약접수가 진행된다. 오피스텔은 3월27일부터 4월1일까지 청약을 한다. 아파트 1순위 청약자격은 청약통장 가입기간 6개월 이상과 청약예치금 250만 원 이상이며 대구 및 경북 6개월 이상 거주자에게 우선 공급된다. 더불어 계약금 10%, 중도금 무이자 혜택이 주어지며 6개월 후 전매가 가능하다. 모델하우스는 달서구 장기동 119-8번지에서 공개 중이다. 태왕이 지난 22일 공개한 ‘성당 태왕아너스 메트로’ 모델하우스를 찾은 방문객의 행렬이 이어진 모습.
- 요약문
태왕의 ‘성당 태왕아너스 메트로’모델하우스는 초역세권 입지와 변화하는 라이프스타일에 맞춘 혁신평면으로 오픈 당일부터 관람객의 줄이 이어지면서 관람객의 호평을 받았다.
학습
본인한테 맞는 파라피터를 설정하고 학습을 시작하면 아래와 같이 학습이 시작된다.
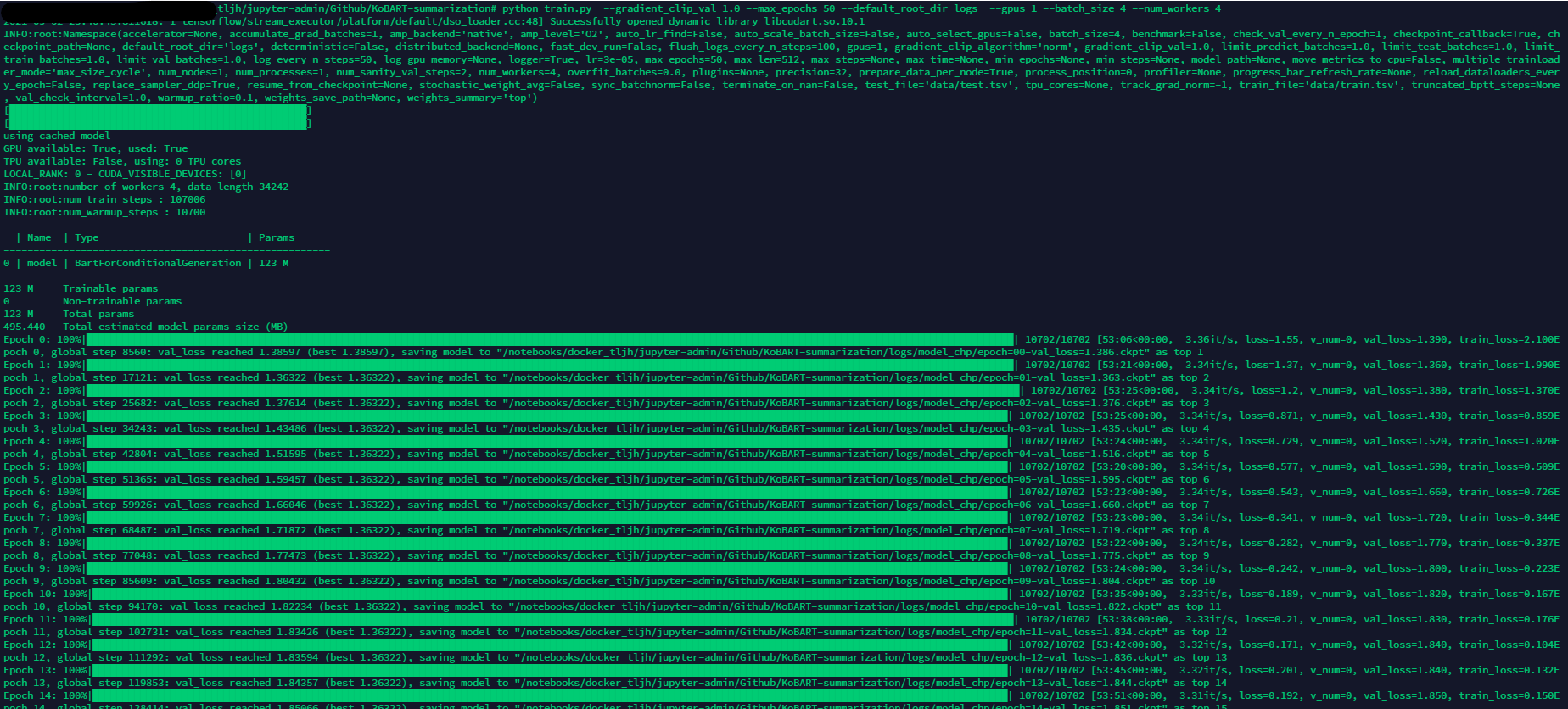
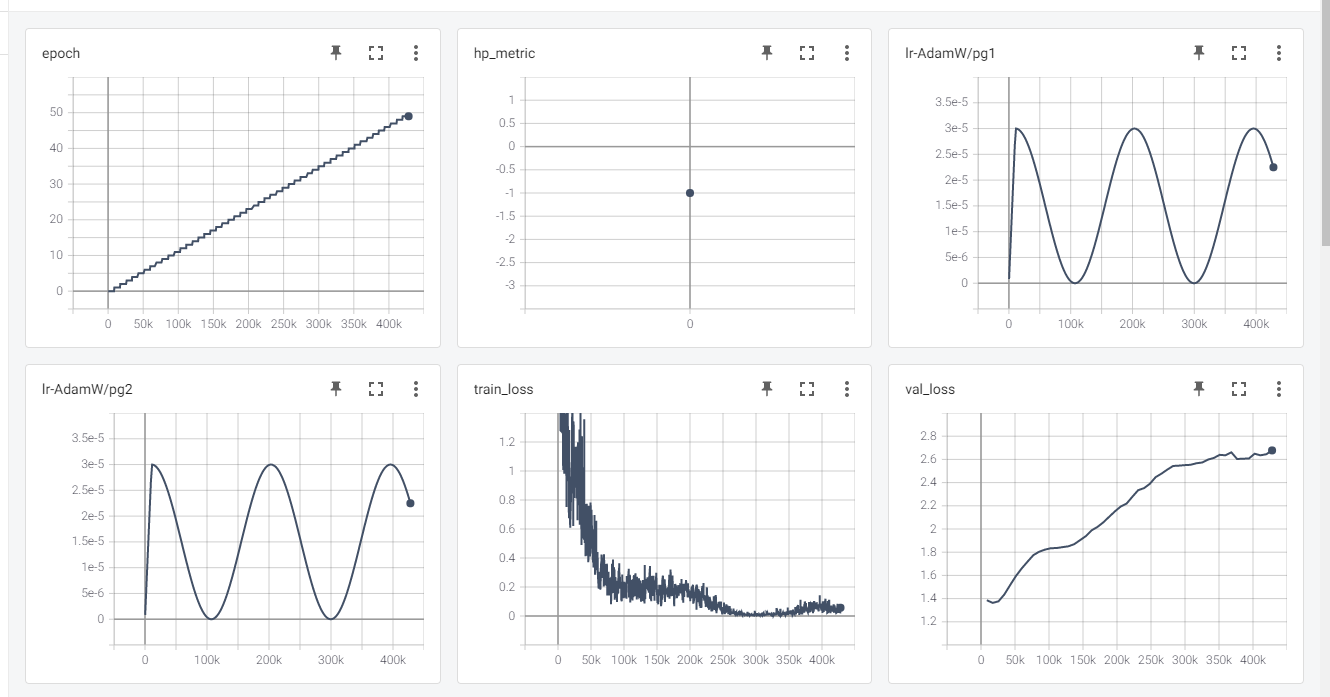
학습 과정
에폭 0 부터 49까지 아래 원문을 어떻게 바꾸는지 눈으로 확인하면 감이 잡힐 것이다.
기사 원문 링크 : SK텔레콤, 국립국어원와 ‘AI 언어능력평가대회’ 개최한다 @김경영 기자 승인 2021.09.01 09:57
- 원문
SK텔레콤은 우리말 인공지능(AI) 언어모델의 개발 역량 향상과 국어 정보화 저변 확대를 위해 ‘인공지능 언어 능력 평가 대회’를 개최한다고 1일 밝혔다. 이번 대회는 SK텔레콤·문화체육관광부·국립국어원 함께 주최한다. 대회는 9월 1일 오후 SK텔레콤의 기본 AI 언어모델과 국립국어원의 평가 데이터 세트 공개와 함께 시작되며, 참가자들은 오는 9월 15일부터 11월 1일까지 결과물을 수시로 업데이트하여 제출할 수 있다. 이번 대회는 개인 또는 팀으로 누구나 참가할 수 있다. 참가팀 중 대상(문화체육관광부 장관상), 금상·은상·동상, 특별상을 선정할 계획이며, 수상자 전원에게는 매년 SK텔레콤이 개최하는 AI 펠로우십(Fellowship)의 서류 심사 면제 특권도 제공할 계획이다. 참가자들은 제공된 언어 모델 등을 기반으로 각각의 AI 언어모델 프로그램을 개발하여 우리말을 이해하고 분석하는 능력을 평가받는다. 제출된 언어모델을 평가하는 과제는 4가지다. ▲문장의 문법 오류 판단하기(문장 적법성 판단) ▲맥락별 단어 의미 구별하기(동형이의어 구별) ▲문장 읽고 원인 추론하기(인과 관계 추론) ▲제시문 읽고 질문에 예/아니오 답하기(판정 의문문) 등이다. 이번 평가는 지금까지 한국어 인공지능 모델 평가를 위해 공개된 데이터세트들보다 난이도가 다소 높은 내용으로 구성됐다. SK텔레콤에서 제공하는 언어모델은 매개 변수가 12억개인 모델이다. 지난해 공개한 KoGPT2 모델보다 약 8배 크다. 이는 SK텔레콤이 국립국어원과 진행하고 있는 한국어 범용언어모델(GLM) 연구 과제의 초기 산출물로, 기존에 SK텔레콤이 개발해 발표한 KoBERT, KoGPT2, KoBART 모델에 이어 한국어 AI 모델을 개발·활용하고자 하는 이들에게 도움이 될 것으로 기대된다. 에릭 데이비스 SK텔레콤 Language Superintelligence Labs장은 “SK텔레콤과 국립국어원이 협업하여 준비한 이번 경진대회가 언어와 AI에 대한 역량을 맘껏 펼치는 장이 되길 기대한다”며 “나아가 이러한 건전한 경쟁이 범용언어모델을 비롯한 한국어 언어모델의 발전과 국어 정보화 확산에 기여하길 바란다”고 말했다.
- Epoch : 0 Val loss: 1.386
SK텔레콤은 우리말 인공지능(AI) 언어모델의 개발 역량 향상과 국어 정보화 저변 확대를 위해 9월 1일 오후 SK텔레콤·문화체육관광부·국립국어원 함께 주최하는 ‘인공지능 언어 능력 평가 대회’를 개최한다고 밝혔다.
- Epoch : 9 Val loss: 1.804
SK텔레콤은 SK텔레콤·문화체육관광부·국립국어원과 함께 ‘우리말 인공지능(AI) 언어모델의 개발 역량 향상과 국어 정보화 저변 확대를 위해 ‘인공지능 언어 능력 평가 대회’를 개최하며, 참가자들은 제공된 언어 모델 등을 기반으로 각각의 AI 언어모델 프로그램을 개발하여 우리말을 이해하고 분석하는 능력을 평가받는다.
- Epoch : 19 Val loss: 2.017
SK텔레콤은 SK텔레콤·문화체육관광부·국립국어원이 함께 주최하는 ‘인공지능 언어 능력 평가 대회’를 개최한다고 밝혀 개인 또는 팀으로 누구나 참가할 수 있고, 참가자들은 9월 15일부터 11월 1일까지 결과물을 수시로 업데이트하여 제출할 수 있다.
- Epoch : 29 Val loss: 2.447
SK텔레콤은 SK텔레콤과 문화체육관광체육관광부·국립국어원이 국어 정보화 저변 확대를 위해 9월 1일 오후 SK텔레콤의 기본 AI 언어모델과 국립국어원의 평가 데이터 세트를 공개하고 9월 15일부터 11월 1일까지 결과물을 수시로 업데이트하여 제출하는 ‘인공지능 언어 능력 평가 대회’를 개최한다고 1일 밝혔다.
- Epoch : 39 Val loss: 2.613
SK텔레콤은 우리말 인공지능(AI) 언어모델의 개발 역량 향상과 국어 정보화 저변 확대를 위해 9월 1일 오후 SK텔레콤의 기본 AI 언어모델과 국립국어원의 평가 데이터 세트를 공개하고 9월 15일부터 11월 1일까지 결과물을 수시로 업데이트하여 제출할 수 있는 ‘인공지능 언어 능력 평가 대회’를 개최한다고 1일 밝혔다.
- Epoch : 49 Val loss: 2.677
SK텔레콤은 SK텔레콤과 문화재체육관광부·국립국어원이 함께 주최하고 국어 정보화 저변 확대를 위해 공동 주최하는 ‘공지능 언어 능력 평가 대회’를 개최한다고 밝히며 참가자들은 9월 15일부터 11월 1일까지 결과물을 수시로 업데이트하여 제출할 수 있다.
각자 요약마다 나름의 매력이 있음.
Demo
1
2
3
python get_model_binary.py --hparams ./logs/tb_logs/default/version_0/hparams.yaml --model_binary ./logs/model_chp/epoch\=49-val_loss\=2.677.ckpt
streamlit run infer.py
위 코드를 실행하면 어디로 접속해야 볼 수 있는지 주소가 뜰 것이다. 만약 streamlit 실행시 웹에서 아래와 같은 오류가 발생한다면,
1
2
3
4
5
6
7
8
9
10
11
UnhashableTypeError: Cannot hash object of type torch.nn.parameter.Parameter, found in the return value of load_model().
While caching the return value of load_model(), Streamlit encountered an object of type torch.nn.parameter.Parameter, which it does not know how to hash.
To address this, please try helping Streamlit understand how to hash that type by passing the hash_funcs argument into @st.cache. For example:
@st.cache(hash_funcs={torch.nn.parameter.Parameter: my_hash_func})
def my_func(...):
...
If you don't know where the object of type torch.nn.parameter.Parameter is coming from, try looking at the hash chain below for an object that you do recognize, then pass that to hash_funcs instead:
@st.cache 이 부분을 @st.cache(hash_funcs={torch.nn.parameter.Parameter: lambda _: None}) 이걸로 바꿔주면 실행될 수 있다.
1
2
3
4
5
@st.cache
def load_model():
model = BartForConditionalGeneration.from_pretrained('./kobart_summary')
# tokenizer = get_kobart_tokenizer()
return model
1
2
3
4
5
6
# @st.cache
@st.cache(hash_funcs={torch.nn.parameter.Parameter: lambda _: None})
def load_model():
model = BartForConditionalGeneration.from_pretrained('./kobart_summary')
# tokenizer = get_kobart_tokenizer()
return model

데이터 더해서 추가학습
KoBART-Summarization repo로 공유해준 데이터는 생각보다 작다.
- train-set : 34,242
- test-set : 8,561
여기에 이것저것 데이터 추가해서 재학습 하고 싶으면,
train.py 소스코드에서 BartForConditionalGeneration.from_pretrained 이부분을 수정해주면 된다.
아쉽게도 제작자분이 prams로 안만드신것 같다.
주의할 점은 ckpt 체크포인트가 아니라 get_model_binary.py 를 통해서 나온 바이너리 파일의 폴더 경로이다.
1
2
3
4
5
6
7
8
9
10
class KoBARTConditionalGeneration(Base):
def __init__(self, hparams, **kwargs):
super(KoBARTConditionalGeneration, self).__init__(hparams, **kwargs)
# self.model = BartForConditionalGeneration.from_pretrained(get_pytorch_kobart_model())
self.model = BartForConditionalGeneration.from_pretrained("/어쩌고저쩌고/KoBART-summarization/kobart_summary")
self.model.train()
self.bos_token = '<s>'
self.eos_token = '</s>'
self.pad_token_id = 0
self.tokenizer = get_kobart_tokenizer()
필자는 약 30만건의 데이터셋을 구해다가 추가학습을 진행했는데 기존 서머리 결과보다 좀더 괜찮아 보이게 나왔다. (괜찮다는건 주관)
원문은 위에서 확인!
- 기존 3만건 데이터로만 해서 파라미터를 디폴트로 학습했을 때 마지막 결과
SK텔레콤은 SK텔레콤과 문화재체육관광부·국립국어원이 함께 주최하고 국어 정보화 저변 확대를 위해 공동 주최하는 ‘공지능 언어 능력 평가 대회’를 개최한다고 밝히며 참가자들은 9월 15일부터 11월 1일까지 결과물을 수시로 업데이트하여 제출할 수 있다.
- 데이터 추가해서 재학습 결과
SK텔레콤은 우리말 인공지능(AI) 언어모델의 개발 역량 향상과 국어 정보화 저변 확대를 위해 ‘인공지능 언어 능력 평가 대회’를 개최한다고 1일 밝혔으며, 이 대회는 9월 1일 오후 SK텔레콤의 기본 AI 언어모델과 국립국어원의 평가 데이터 세트 공개와 함께 시작되며, 참가자들은 오는 9월 15일부터 11월 1일까지 결과물을 수시로 업데이트하여 제출할 수 있다.